Projects
DeepRoute: Experimenting with Large-scale Reinforcement Learning and SDN on Chameleon Testbed and Mininet
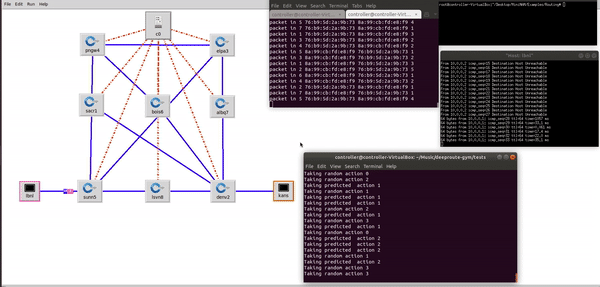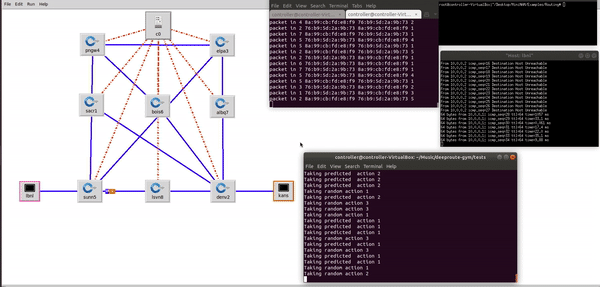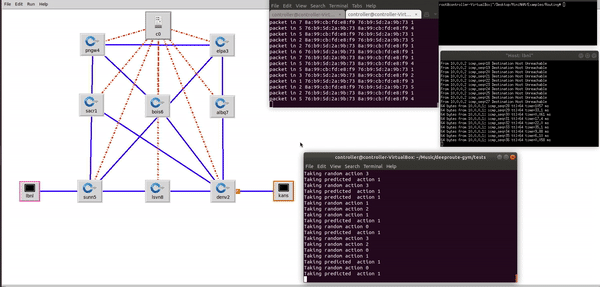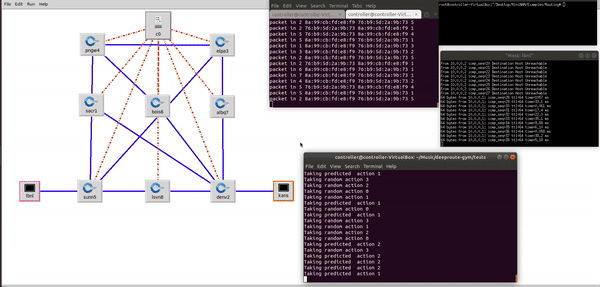
Demo showing DeepRoute agent exploring and exploiting the different network paths from LBNL to KANS and selecting the most optimal network path considering the different traffic contions such as bandwitdth, throuput and latency. DeepRoute Agent has a global view of all the location(nodes), where each network location corresponds to a node, edges are the connectivity between the nodes and, the edge weights are the distance. Paper1 , Paper2 , Talk.
DynamicDeepFlow: An Approach for Identifying Changes in Network Traffic Flow Using Unsupervised Clustering
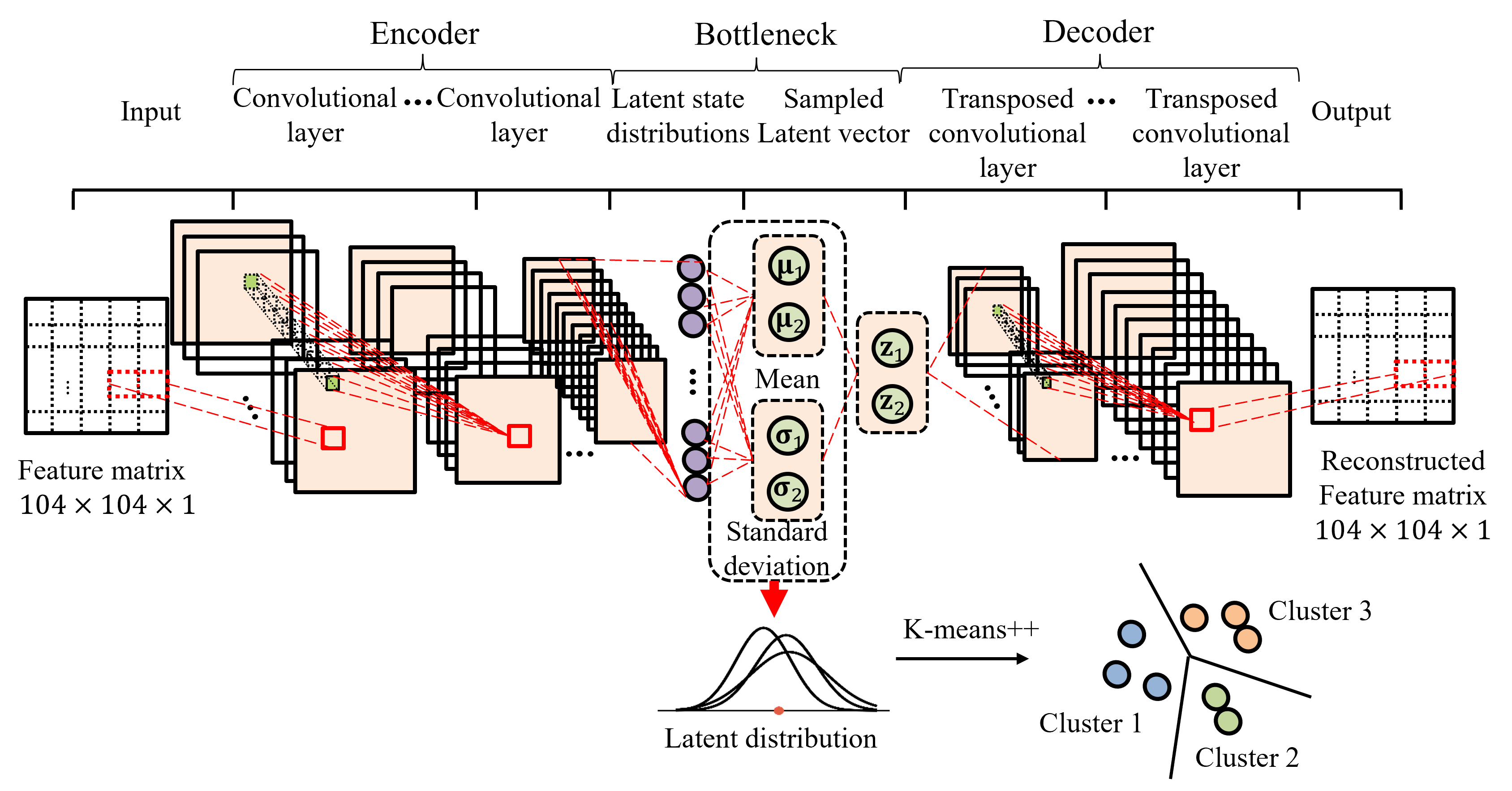
Understanding flow changes in network traffic has great importance in designing and building robust networking infrastructure. Recent efforts from industry and academia have led to the development of monitoring tools that are capable of collecting real-time flow data, predicting future traffic patterns, and mirroring packet headers. These monitoring tools, however, require offline analysis of the data to understand the big versus small flows and recognize congestion hot spots in the network, which is still an unfilled gap in research.
NetPredict: Real-time Deep Learning Predictions for Network Traffic Forecasting
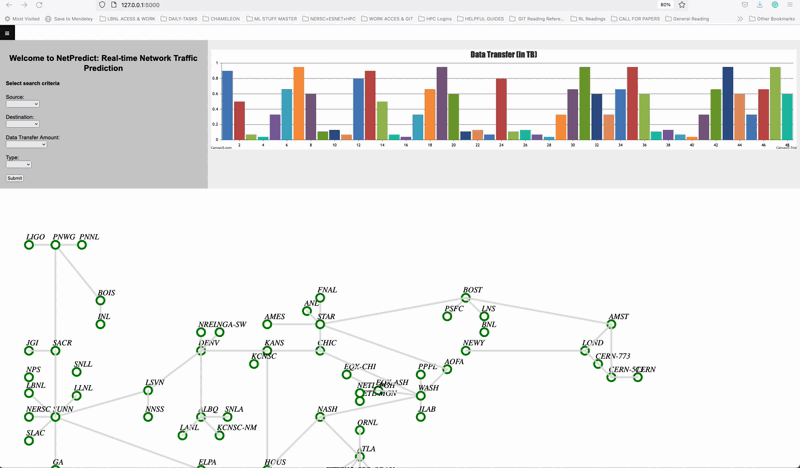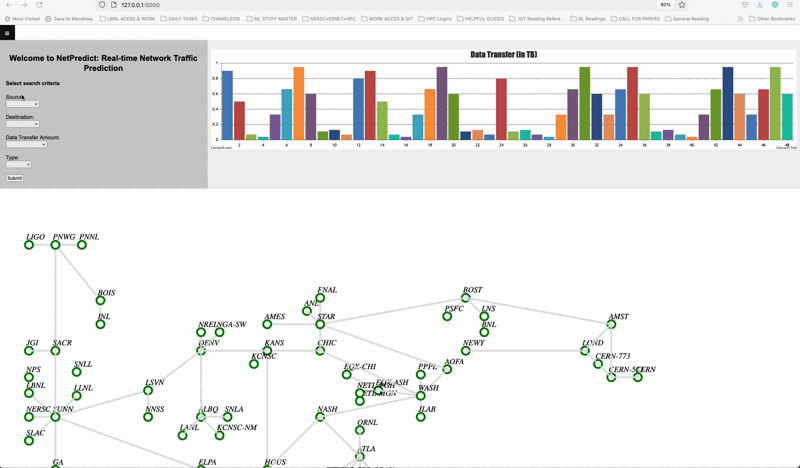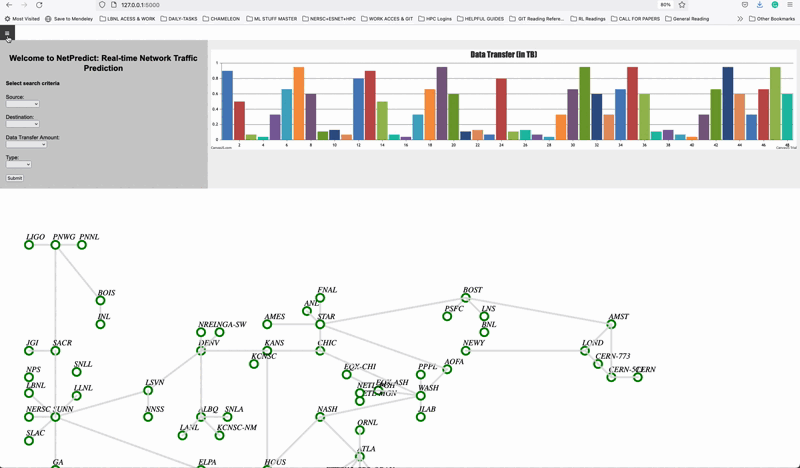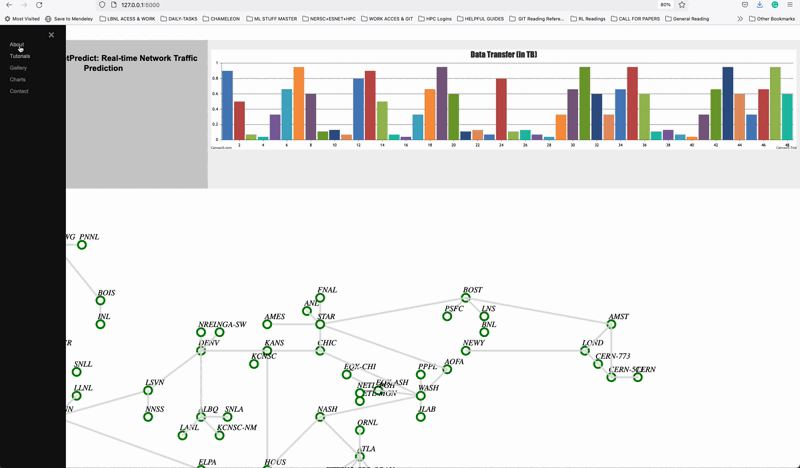
NetPredict Demo showing the Graphical user interface. A source and destination is been selected and the most optimal network path is calculated considering the different traffic contions such as bandwitdth, throuput and latency. NetPredict is focused on predicting hourly, weekly and monthly, and it allows users to deploy their deep learning or statistical prediction models to predict link bandwidth and measure how well they are performing in real-time. Link.
Deep Reinforcement Learning based Control for two-dimensional Coherent Laser beam Combining
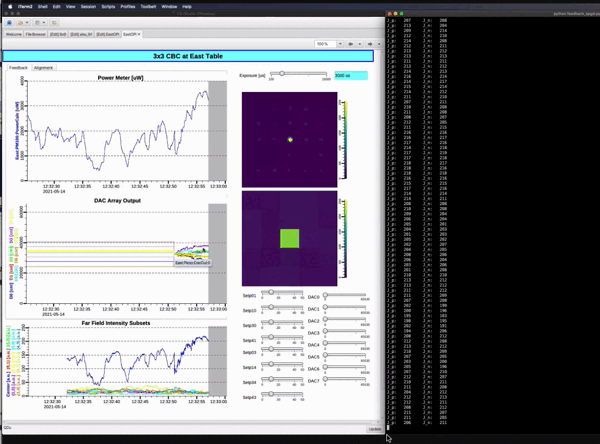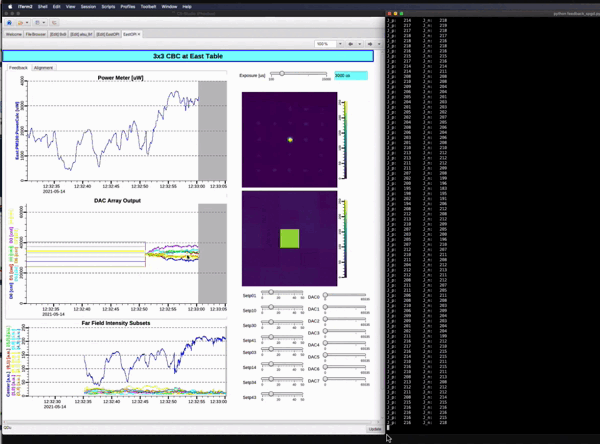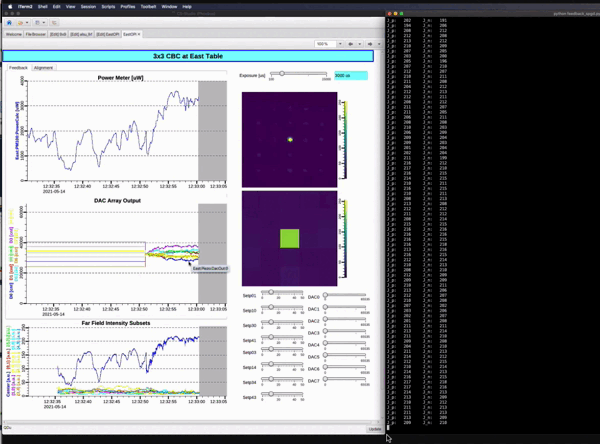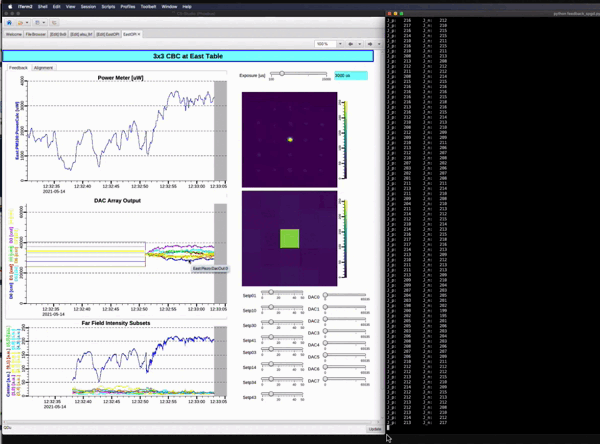
Demo showing Snapshot of the real-setup and how stability is achieved keeping the center beam intensity highest. In the real system for example, the noise bandwidth is about 100Hz and the sample rate is kHz, and we have 100s of these laser beams. So,fast feedback is needed to control and stabilize the system against unwanted noise in real-time. The main objective is to always keep the center beam intensity highest irrespective of the environmental pertubations. Paper1 , Paper2 , Paper3.
Dynamic Graph Neural Network for Traffic Forecasting in Wide Area Networks
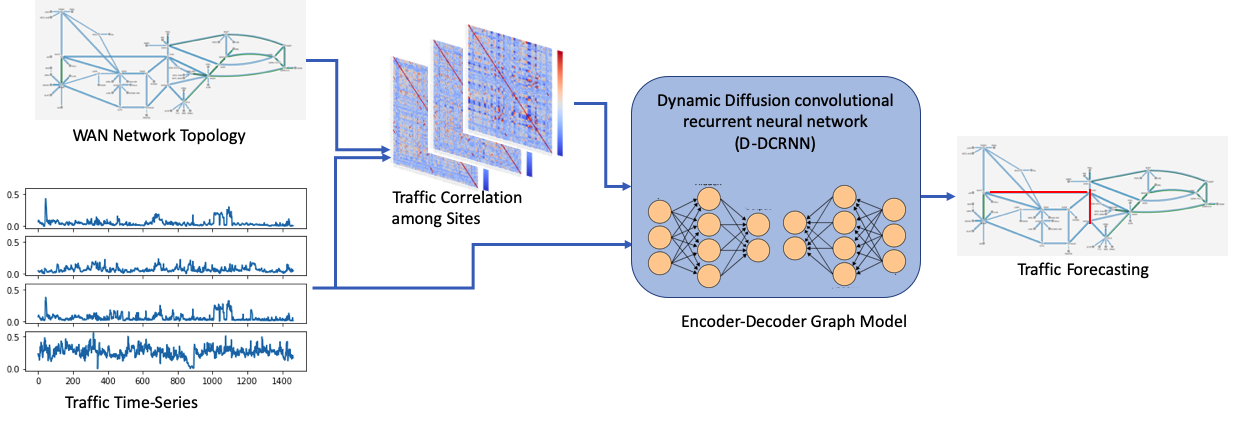
Dynamic-DCRNN (D-DCRNN) model architecture. It takes an adjacency matrix computed from the current state of the network traffic amongthe sites of the WAN network topology and the traffic as a time-series at each node of the graph. The encoder-decoder deepneural network is used to forecast the network traffic for mutiple time steps. Paper.
NetGraf: An End-to-End Learning Network Monitoring Service
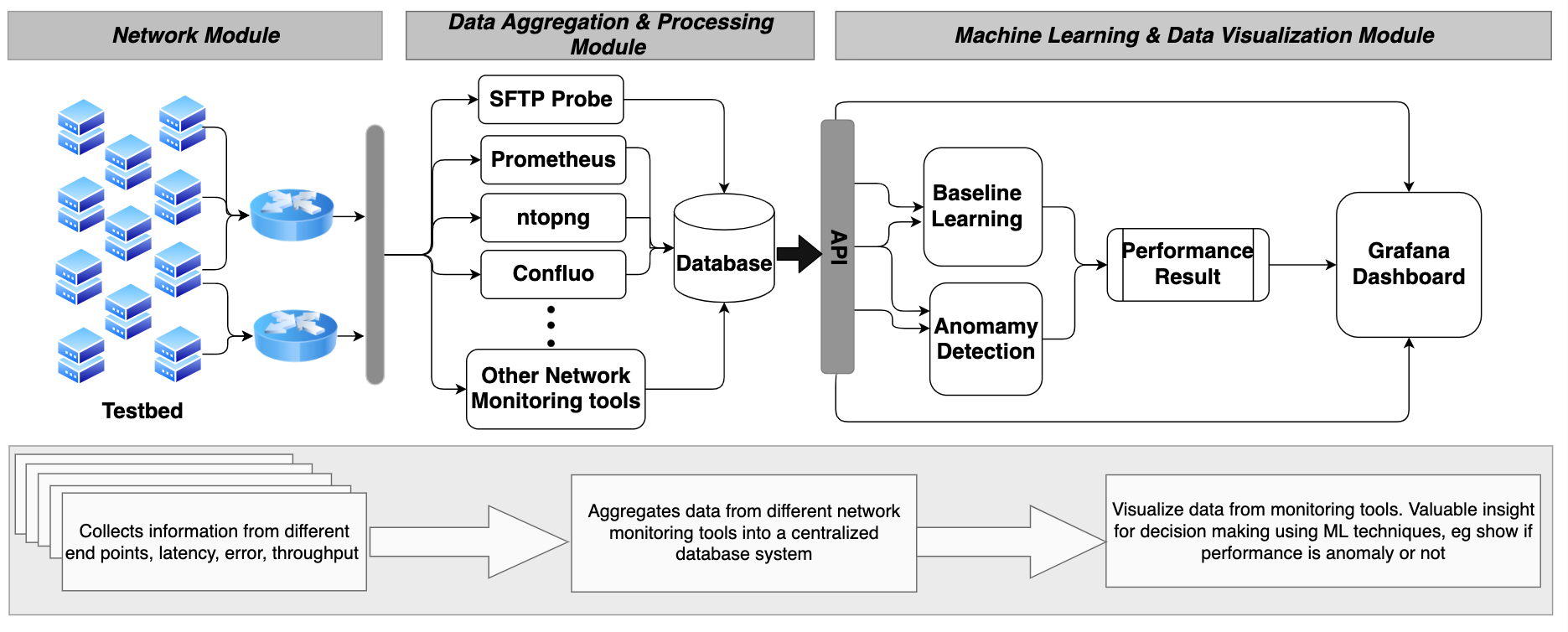
Net-Preflight Check: Using File transfer to Measure Network Performance before Large Data Transfers
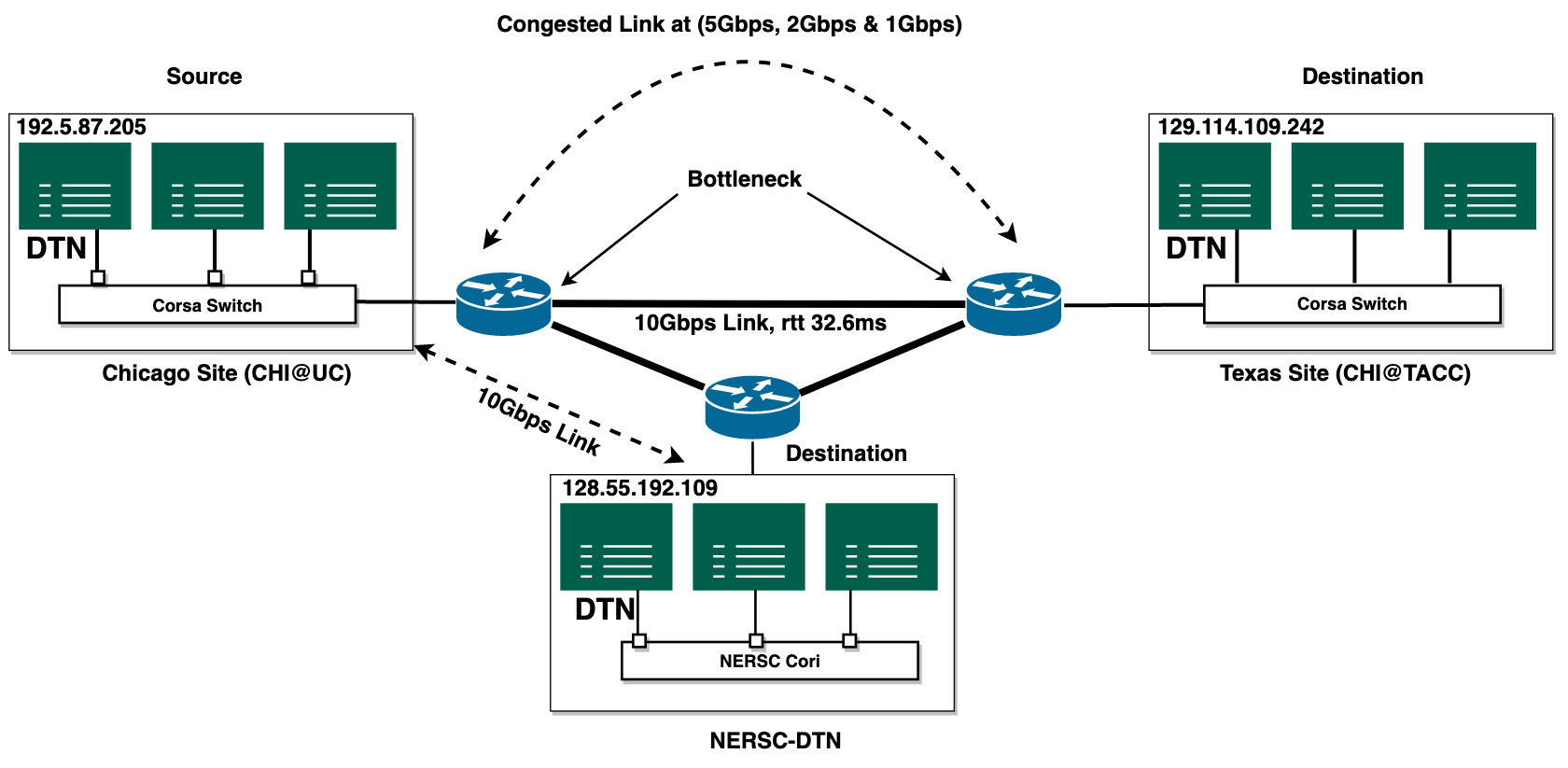
Throughput measurement for large data transfer over isolated Network (CHI@UC to CHI@TACC) and public Network (NERSC DTN to CHI@UC DTN).
DeepRoute Mininet Implementation: Herding Elephant and Mice Flows with Reinforcement Learning
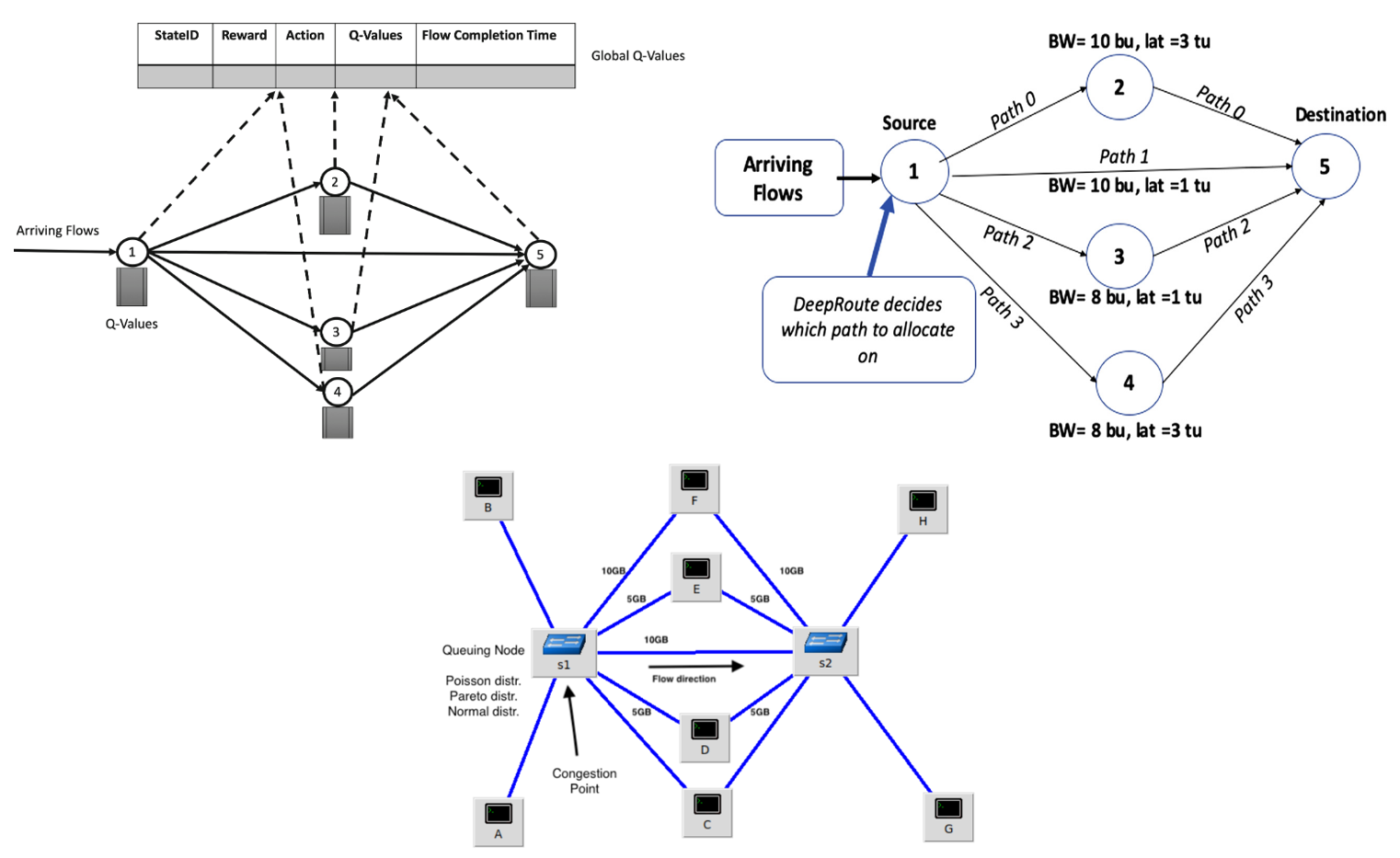
Topology used in the Simulation Model (bu = bandwidth units occupied and tu = time units occupied), Q-values for Local and Global levels. Paper
Predicting WAN traffic volumes using Fourier and multivariate SARIMA approach
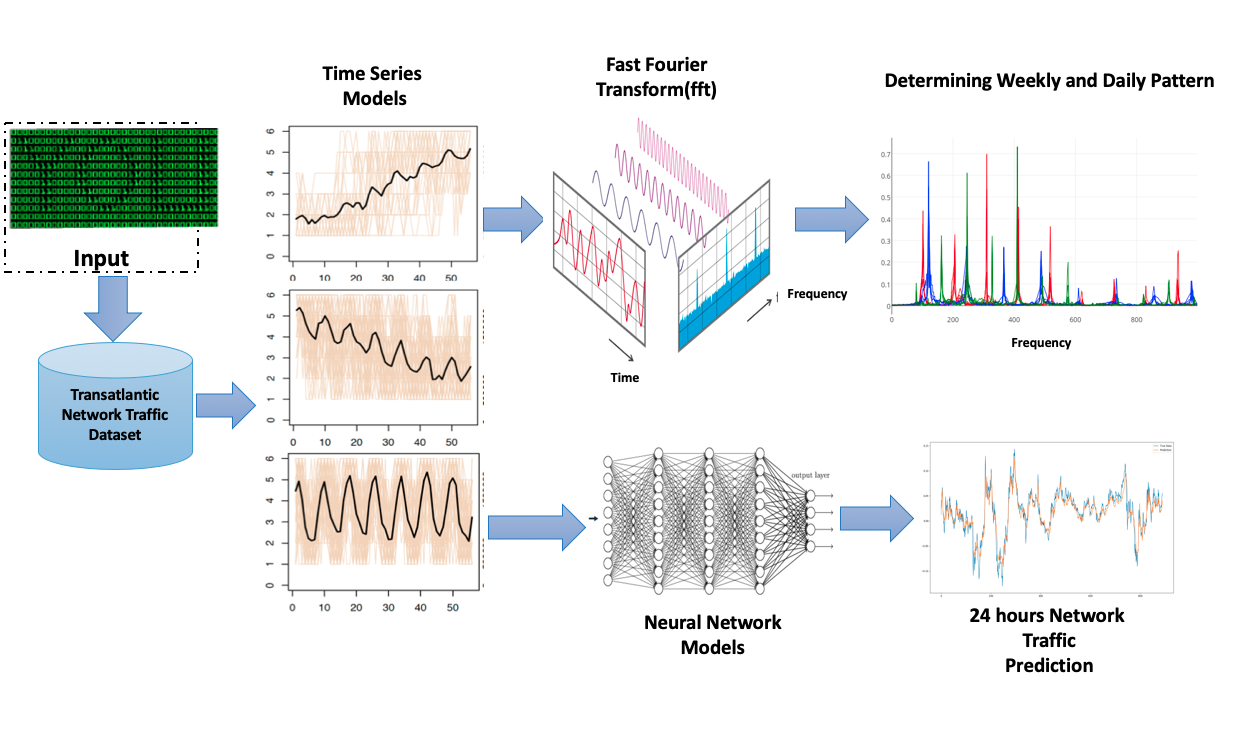
Studying network traffic as a time-series problem. using FFT to extract frequency patterns across the traffic traces, to validate the variability among the traces used in this study FFT extracts symmetry frequencies for signals, as finite sum of sine waves. A variation of discrete Fourier transformation equation (DFT), helps extract positive frequencies in the dataset. Paper
Failure prediction using machine learning in a virtualised HPC system and applicationh
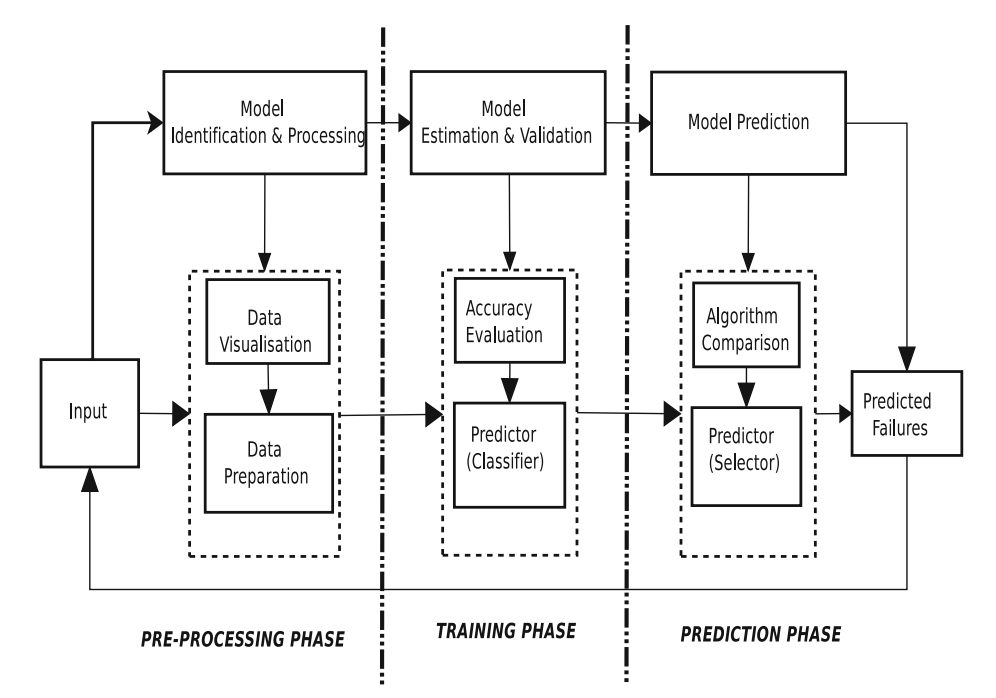
Proposed system model and architecture. Failure prediction using machine learning in a virtualised HPC system and application. Paper
Failover strategy for fault tolerance in cloud computing environment
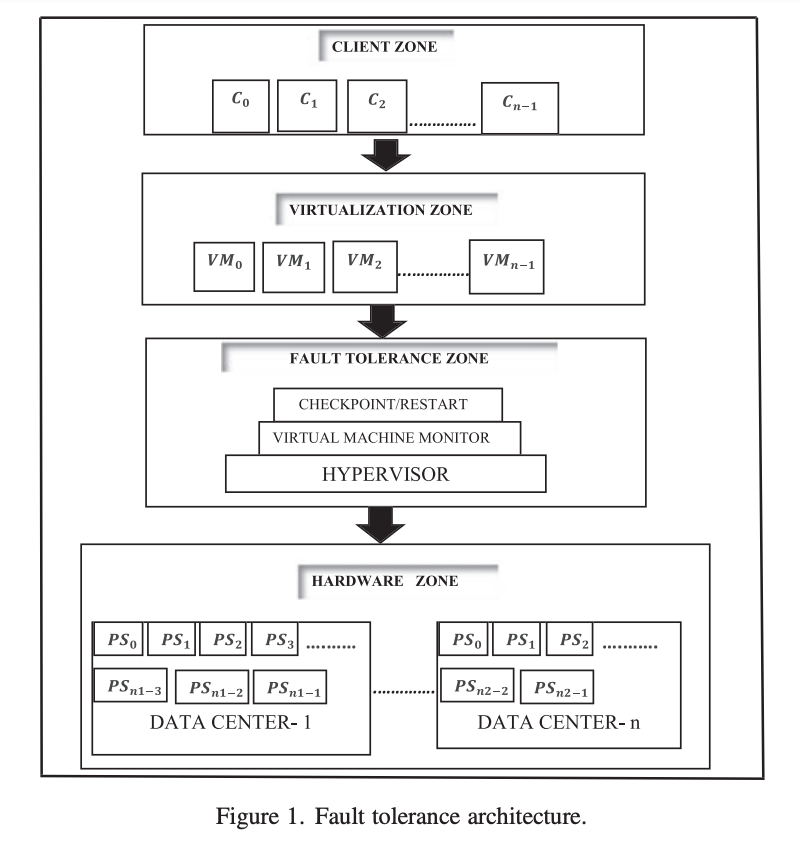
Fault tolerance architecture. The FT model (FTm) of a cloud computing system is represented by a finite-ordered list of elements or a sequence of five elements. Paper